WAF latency in EU/Asia/US East
Postmortem
Degraded Global Performance / Localized Outages - October 14th - 16th
Between October 14th and October 16th our network experienced multiple DDoS attacks that caused performance degradation and localized outages in specific regions during different times for three days period. We were able to mitigate the attack partially during the first 2 days and fully mitigated it on the 16th.
The attack continues today, but there has been no further impact to the network or our customers.
TL;DR:
This outage was as a direct result of a series of unfortunate events:
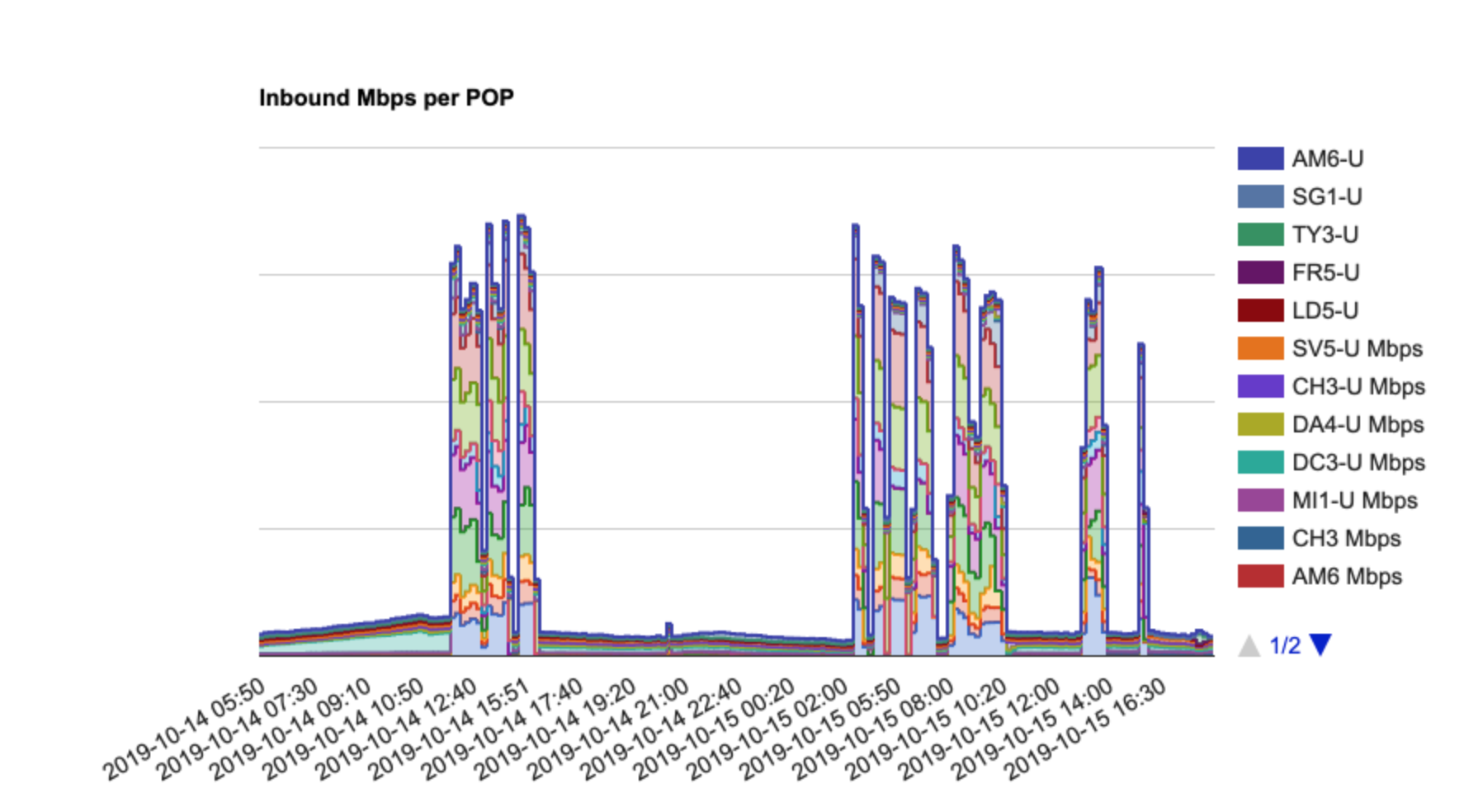
- Distributed Denial of Service (DDoS), a volumetric UDP Flood attack that saturated the network in specific regions;
- Infrastructure, architecture and partnership challenges that resulted in failsafes 1 and 2 being unavailable.
Starting on October 14th attackers initiated a large volumetric attack, also known as a Distributed Denial of Service (DDoS), in the form of a UDP flood (amplification) attack. This attack is a game of who has bigger pipes as it inundates the target network with spoofed UDP packets.
October 14th and 15th:
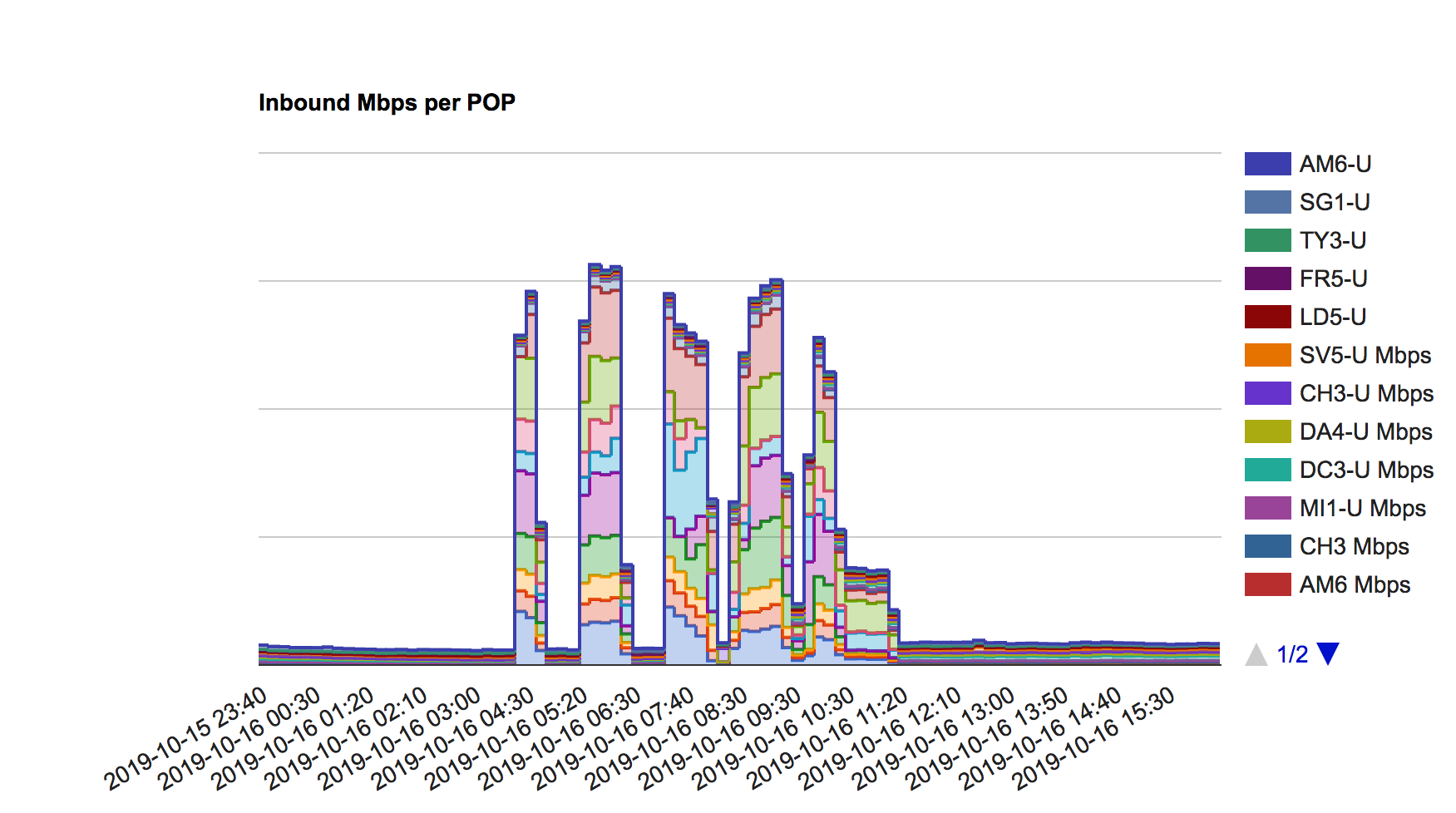
October 16th:
 The degraded performance and outages were regionalized at different times. Below are the regions affected:
The degraded performance and outages were regionalized at different times. Below are the regions affected:
Europe
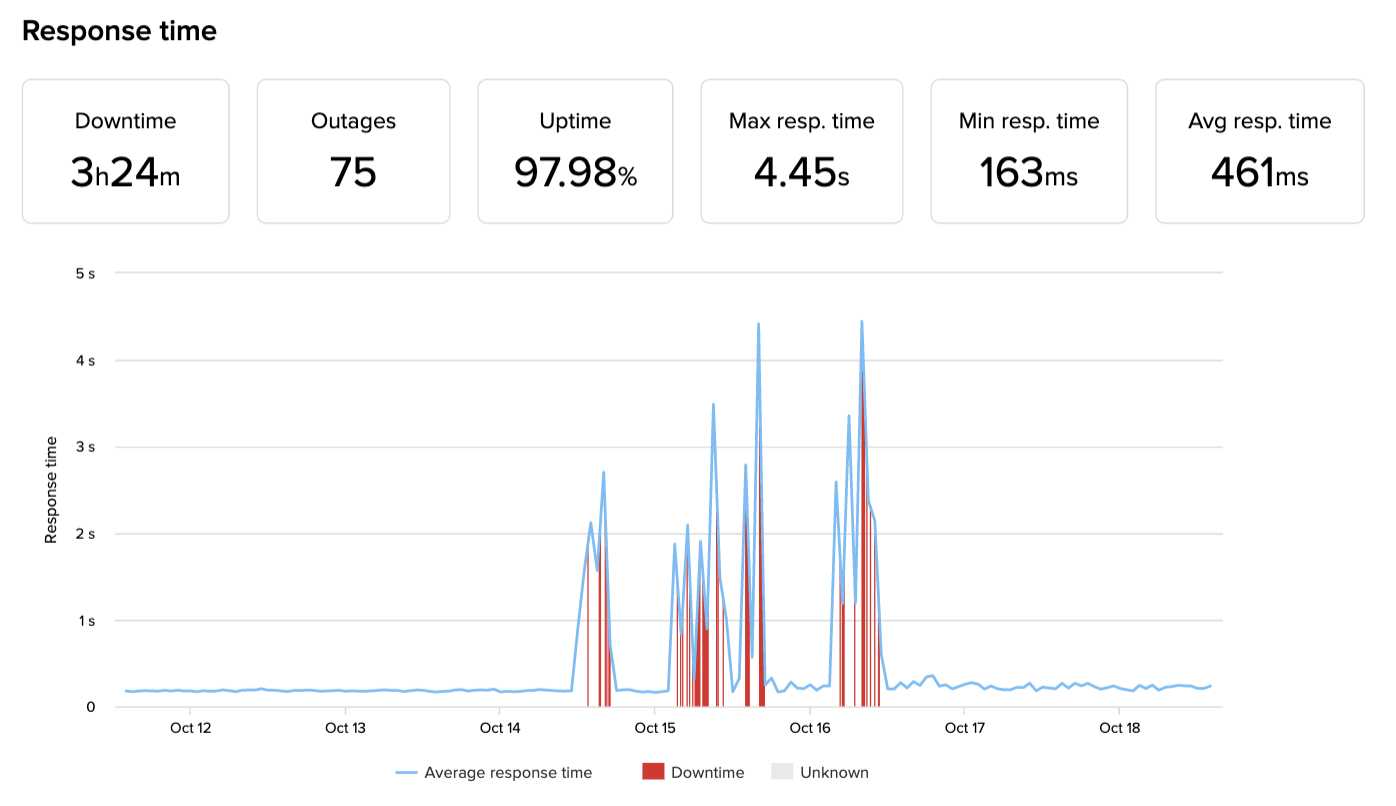
Asia
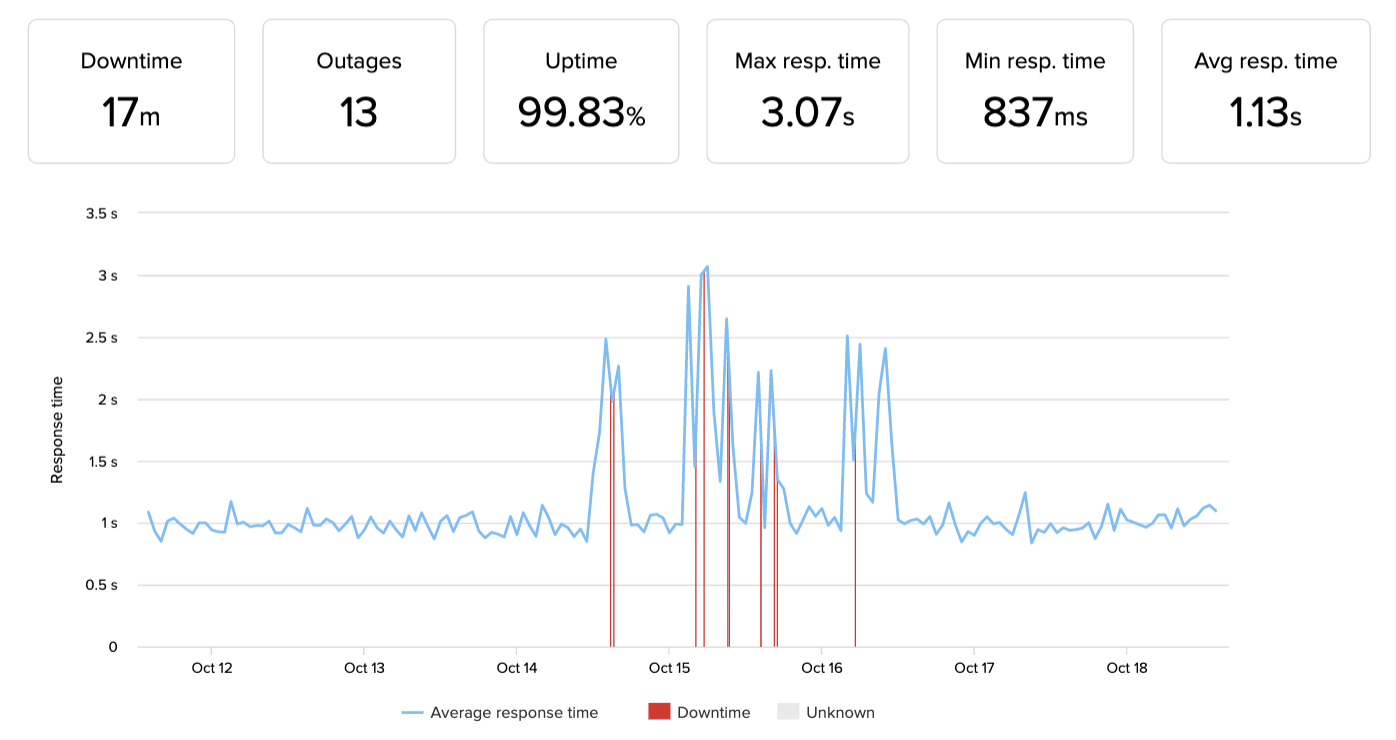
Latin America
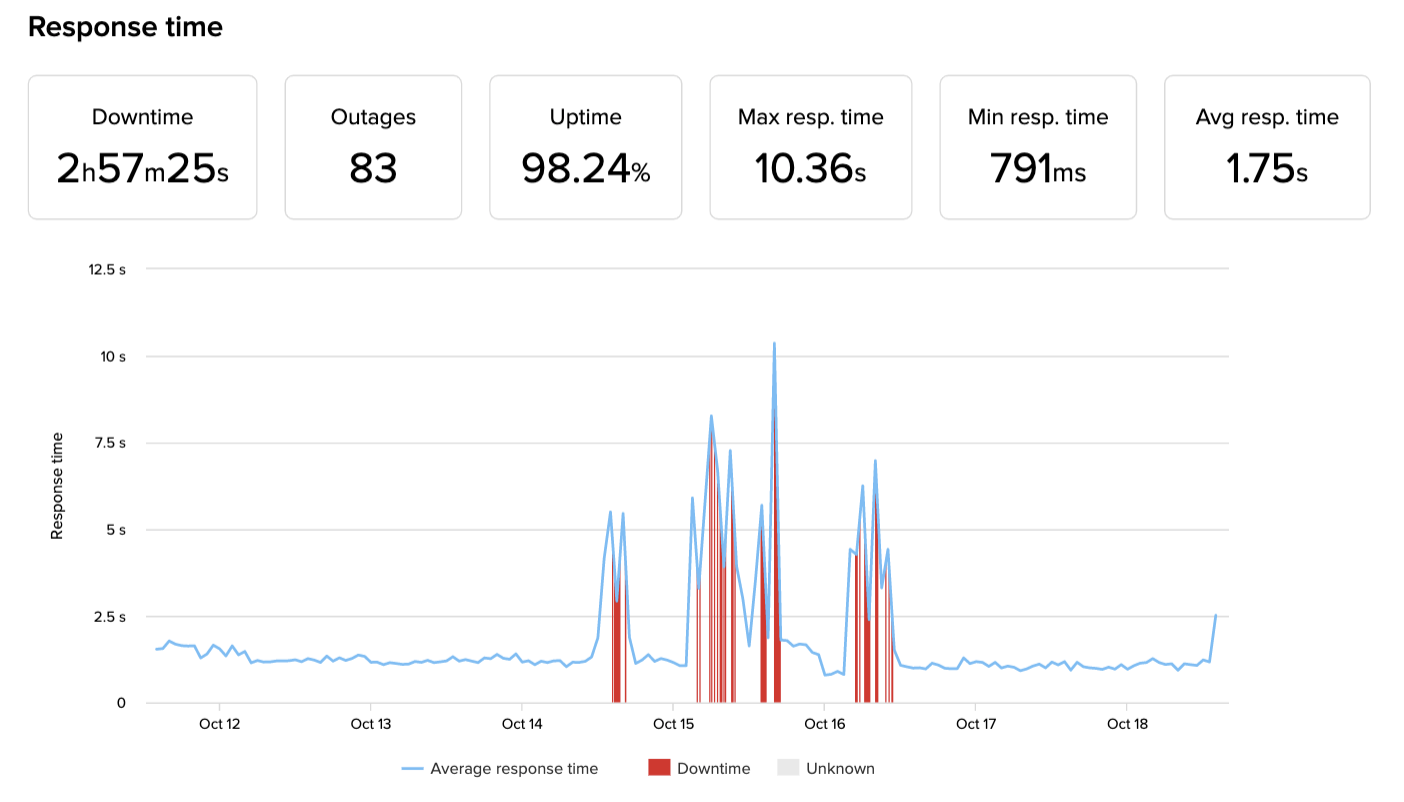
North America
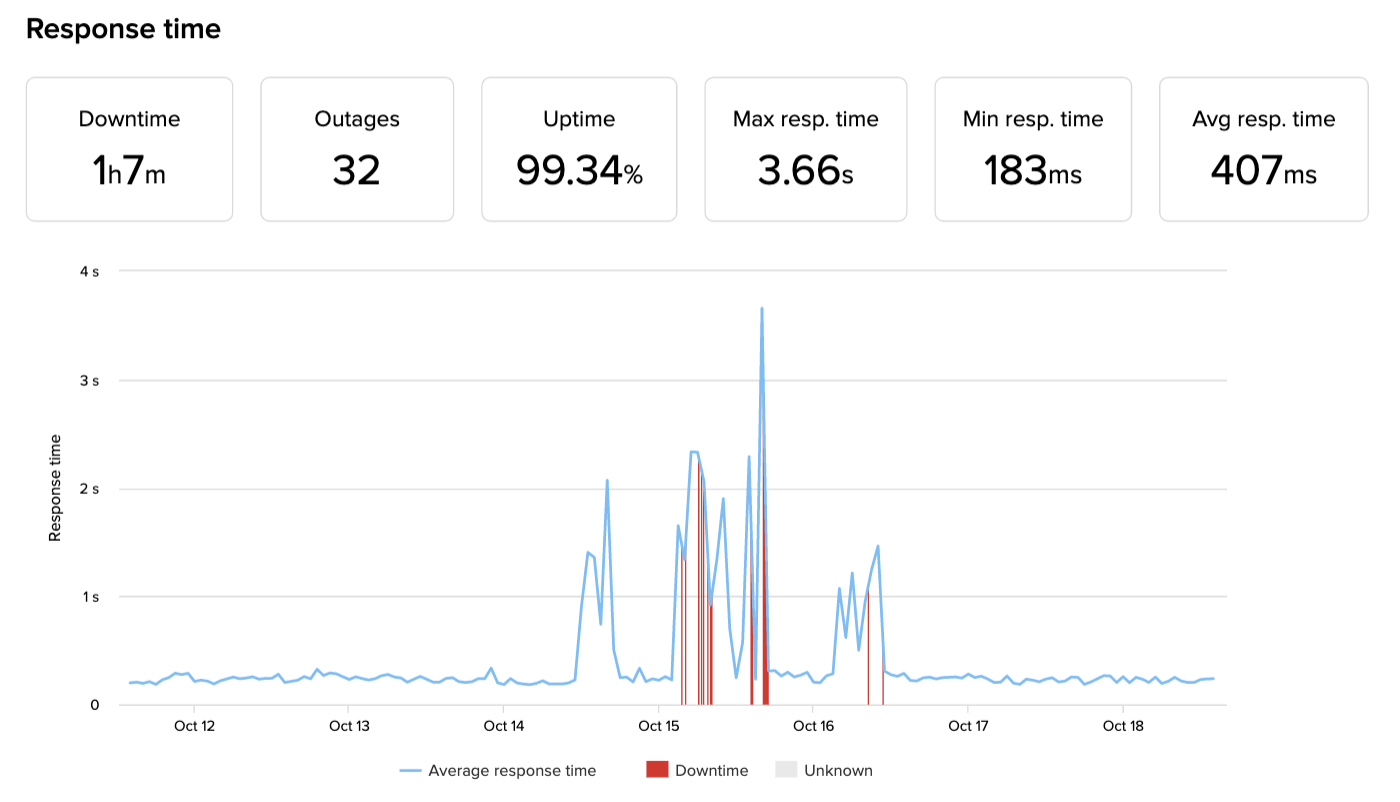 So what happened? We experienced a large DDoS that saturated parts of our network, and a series of unforeseen circumstances throughout the chain contributed to the total impact (both in number of customers affected and global performance).
So what happened? We experienced a large DDoS that saturated parts of our network, and a series of unforeseen circumstances throughout the chain contributed to the total impact (both in number of customers affected and global performance).
Will you share more details? No, because of the nature of the attack. It is still ongoing and being mitigated, so we don’t want to share information that an attacker can use to enhance their attack to circumvent the mitigation controls.
Steps to Improve Our Mitigating Controls and Processes
Technical:
- We are revisiting some of our architecture decisions and initiating a series of work streams to reconfigure and better optimize our network configuration in key regions. Some of the work has already been completed, and was instrumental in our mitigation of this attack. This new design should help alleviate this, and similar, types of attacks in the future.
- We will continue to work on our global expansion efforts, placing weight on key geographic regions.
Communication:
We have a lot of room to improve in our communication. After every incident we get better, but it’s not materially better. We deal with DDoS attacks every day. but it is very rare for one of them to have this impact.
We recognize that at our scale there is an expectation of more frequent updates; we have put together a team that will focus on building a framework for how we handle incidents in the future.
1.Social engagement:
We have been reading the tweets through the whole process and realize that something we must do is improve our update frequency. Even if the status hasn’t changed, there is a need to provide reassurances that we are still working on it.
2.Proactive Engagement:
Something we’re thinking through is the best way to proactively notify customers of an issue. We’re mapping out specific thresholds that will trigger specific actions
3.Maintaining the status page:
Similar to our social engagement, we recognize the importance of keeping our status page current. What we’re thinking through is the frequency of the updates. We also realize the importance of the accuracy of the updates (if the notes say one thing, but the indicators say something different, that’s a problem). We’re actively discussing the best way to handle that based on the existing configuration of the system.
If you have other recommendations, we would love to hear from you.